
Retrieval-Augmented Generation (RAG) and Large Language Models (LLMs) are two distinct yet complementary AI technologies. Understanding the differences between them is crucial for leveraging their capabilities effectively.
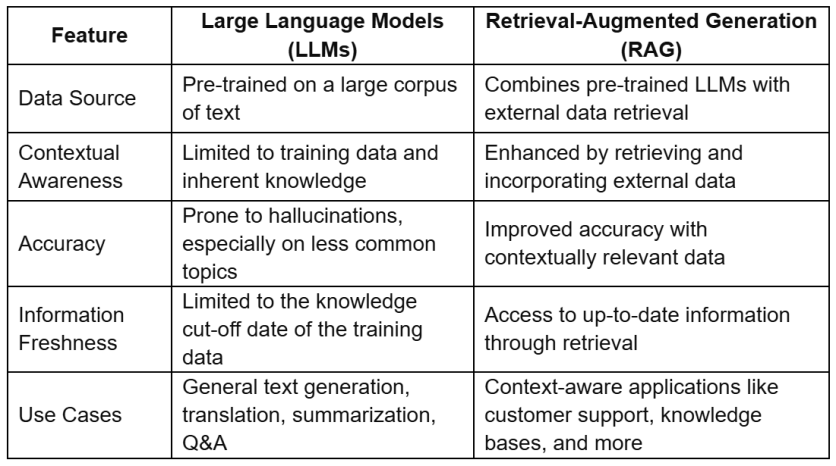
Large Language Models (LLMs)
LLMs, such as GPT-3 and GPT-4, are advanced neural networks trained on vast amounts of text data. They are capable of generating human-like text based on the input they receive. Here are some key aspects of LLMs:
- Training Data: LLMs are pre-trained on diverse datasets encompassing a wide range of topics and language styles. This enables them to generate coherent and contextually relevant text based on their training data.
- Capabilities: They can perform various natural language processing tasks, including text generation, translation, summarization, and question answering.
- Limitations: LLMs sometimes produce hallucinations, where they generate plausible-sounding but incorrect or nonsensical answers. They also have limitations in accessing up-to-date information beyond their training cut-off.
Retrieval-Augmented Generation (RAG)
RAG enhances the capabilities of LLMs by integrating information retrieval techniques. It combines the generative power of LLMs with external data sources (vector databases for isntance) to provide more accurate and context-aware responses.
We've asked experts at Vectorize and they added: "By integrating relevant external data, RAG significantly improves the contextual accuracy of LLMs, reducing the occurrence of hallucinations and providing users with more precise and reliable responses."
Here's how RAG works and its key features:
- Retrieval Component: RAG involves retrieving relevant information from external sources, such as vector databases, based on the user's query. This retrieval process typically uses semantic search techniques to find the most relevant data chunks.
- Augmentation: The retrieved data is then used to augment the prompt given to the LLM. This additional context helps the LLM generate more accurate and relevant responses.
- Generation: The LLM generates a response using the original prompt and the augmented information. This process reduces the likelihood of hallucinations and improves the accuracy of the generated text.
How RAG Enhances LLMs
- User Submits a Prompt: A user submits a query or request to the RAG application.
- Data Retrieval: The RAG system retrieves relevant information from a vector store or database using semantic search.
- Augmentation: The retrieved data is combined with the user's prompt to create an enhanced prompt.
- Response Generation: The augmented prompt is sent to the LLM, which generates a response using both the original and retrieved context.
- Response Delivery: The RAG application sends the generated response back to the user.
Comparison
How Vector Databases Play Into This
What is a Vector Database?
A vector database is a specialized "search engine" designed to manage high-dimensional vectors. These databases perform approximate nearest neighbor (ANN) searches, where a user provides a query vector, and the database retrieves the closest matches from its indexed data.
How Vector Databases Work with RAG
Vector databases store data using vector embeddings, allowing efficient management of high-dimensional vectors. By leveraging techniques such as sharding and partitioning, these databases ensure scalable searches across large data volumes.
In the context of RAG, vector databases play a crucial role by providing the necessary data chunks that augment the LLM's responses, leading to more relevant and accurate answers.
Benefits of Vector Databases
- Similarity Search: Efficiently finds the closest matches to a query vector.
- Handling Large Volumes: Manages extensive collections of vectors with ease.
- Real-time Updates: Supports real-time data updates for dynamic datasets.
The Best Vector Databases for RAG Applications
Pinecone
Pinecone is a managed vector database service that stands out for its scalability and ease of use, particularly suited for RAG applications.
Key Benefits of Pinecone
- Straightforward API: Pinecone offers a simple API for vector search, with usage-based pricing and a free trial. This makes it accessible for developers to integrate and test the service without significant upfront costs.
- Python Support: Provides an easy-to-use Python SDK, making it accessible to developers and data scientists familiar with the Python ecosystem. This allows for seamless integration with existing AI workflows.
- Scalability: Pinecone's architecture is built to scale with growing data and traffic demands, making it an excellent choice for high-throughput applications. It uses advanced indexing and partitioning techniques to manage large datasets efficiently.
Cons of Pinecone
- Managed Service: Dependence on a managed service might be a concern for some users who prefer more control over their infrastructure.
- Limited Advanced Querying: While Pinecone excels at similarity search, it might lack some advanced querying capabilities that certain projects require, which could limit its use in some specialized applications.
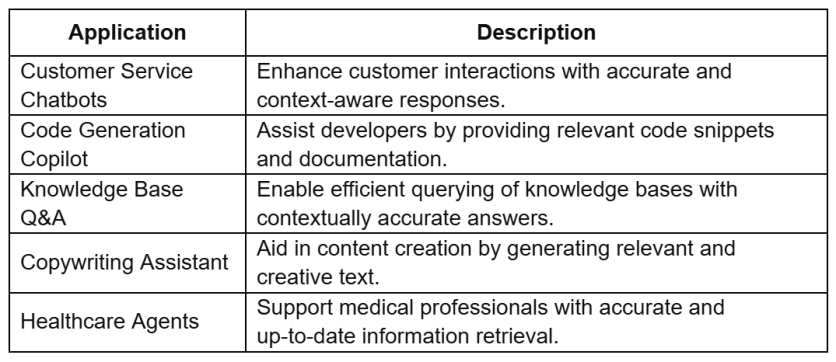
What You Can Build with RAG and Pinecone
RAG combined with Pinecone can be used to create a variety of applications. Here are some potential uses:
Concluding Words
RAG and vector databases represent a major advancement in AI technology, providing more accurate and contextually relevant responses. By leveraging the strengths of vector databases like Pinecone, developers can build scalable and efficient AI applications.
Summary Checklist — Key Takeaways
- RAG enhances LLMs by integrating information retrieval.
- Vector databases specialize in high-dimensional vector searches.
- Pinecone is a leading vector database for RAG applications.
- Vector databases offer benefits like similarity search and real-time updates.
- Applications of RAG and Pinecone include chatbots, knowledge bases, and more.
![Apple Watch Series 10 [GPS 42mm]](https://d.techtimes.com/en/full/453899/apple-watch-series-10-gps-42mm.webp?w=184&h=103&f=9fb3c2ea2db928c663d1d2eadbcb3e52)



