A recent study conducted by University College London (UCL) reveals that humans are only able to detect deepfake speech only 73% of the time, regardless of whether it's in English or Mandarin.
Deepfakes are a form of synthetic media created using generative artificial intelligence (AI) that imitates a real person's voice or appearance. These AI algorithms are trained to replicate original sound or imagery by learning patterns and characteristics from a dataset, such as audio or video of a real individual.
While early versions required extensive data, newer pre-trained algorithms can recreate someone's voice using just a three-second clip, according to the study.
TTS Algorithm
In the UCL study, researchers used a text-to-speech (TTS) algorithm trained on publicly available datasets in English and Mandarin to generate 50 deepfake speech samples in each language. These samples were distinct from the data used to train the algorithm to ensure it did not reproduce the original input.
The researchers then played both the artificially generated and genuine speech samples to 529 participants, aiming to assess their ability to identify real from fake speech.
Surprisingly, the participants were only able to detect deepfake speech with a 73% accuracy rate. Even after receiving training to recognize deepfake speech characteristics, their detection accuracy only marginally improved.
Kimberly Mai, the first author of the study, highlights that this finding demonstrates humans' inability to consistently identify deepfake speech, even with training.
Furthermore, the study used relatively older algorithms, raising concerns about human detection capabilities against the most sophisticated technology available now and in the future.
Better Automated Speech Detectors
The research team plans to develop better-automated speech detectors to counter the potential threats posed by artificially generated audio and imagery. While generative AI audio technology does offer benefits, such as increased accessibility for individuals with limited speech abilities, there are also growing fears that criminals and nation-states could exploit this technology to inflict harm on individuals and societies.
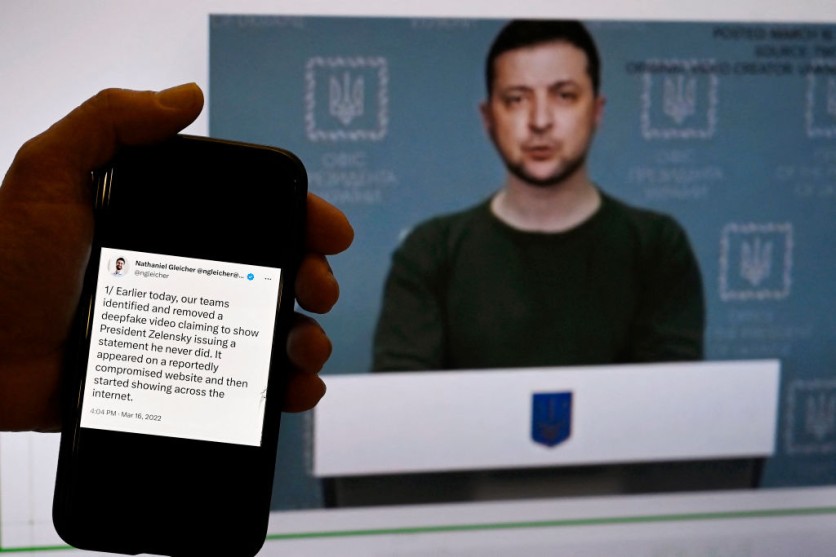
Documented cases of deepfake speech misuse include a 2019 incident where a British energy company's CEO transferred funds to a false supplier after being deceived by a deepfake recording of his boss's voice.
Professor Lewis Griffin, the senior author of the study, emphasizes the need for governments and organizations to devise strategies to address the potential misuse of generative AI technology.
However, he also acknowledges the positive prospects that lie ahead, as this technology has the potential to bring about numerous benefits if used responsibly.
"With generative artificial intelligence technology getting more sophisticated and many of these tools openly available, we're on the verge of seeing numerous benefits as well as risks," Griffin said in a statement.
"It would be prudent for governments and organizations to develop strategies to deal with abuse of these tools, certainly, but we should also recognize the positive possibilities that are on the horizon."
The study's findings were published in the journal PLOS ONE.
Related Article : Nicki Minaj Hopes Internet Gets "Deleted" After Seeing Deep Fake Video of Her, Tom Holland

![Apple Watch Series 10 [GPS 42mm]](https://d.techtimes.com/en/full/453899/apple-watch-series-10-gps-42mm.webp?w=184&h=103&f=9fb3c2ea2db928c663d1d2eadbcb3e52)



